
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.

Bonsoir,
Le 30/10/2023 à 20:33, Jarod G. via FRsAG a écrit :
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Regarde Prometheus (https://prometheus.io/) qui est le truc à la mode (pas testé).
N'oublie pas la supervision sécurité, ne serait-ce que pour lire les logs et corréler des événements. Je sais ça paraît dingue mais en vrai ça aide aussi pour le debugging infra et applicatif puisque ça t'oblige à /vraiment/ regarder ce qu'il se passe en profondeur. Et ça ne coûtera pas plus cher si tu t'y prends bien pour mutualiser la supervision. Et ça va t'aider de savoir que le serveur mail s'est fait tabasser donc il n'a pas pu envoyer les messages de supervision pile le jour ultra-important où il fallait que rien ne se passe. :-)
Prévois un secours différent de la messagerie électronique, ça peut être une alerte sur de la messagerie instantanée par exemple (pas Slack qui est illégal en Union Européenne), avec un secours cellulaire (4G/5G) pour l'accès à Internet au cas où... (Ou bien pour envoyer des SMS purement celluaires...)
Un status genre Cachet (https://cachethq.io/) posé chez un autre hébergeur (éventuellement en coopération mutualisée/croisée entre personnes bien éduquées) peut aider aussi. Ça peut toujours aider d'avoir de la supervision hors-les-murs pour valider que tout marche bien de l'extérieur.
Pour finir, l'outillage c'est bien, l'organisation c'est bien aussi. Je ne vais pas défendre ITIL mais définir clairement ce qu'est un événement, un incident, une crise, en définir clairement les enjeux, les parties prenantes, les personnes à prévenir ou pas, le roulement des effectifs, les procédures RH pour gérer les coups durs psychologiques et/ou maintenir des conditions de travail correctes en temps de paix et en temps de guerre, tout ça c'est se donner les moyens de faire mieux au présent et de s'assurer au moins un peu l'avenir.
La supervision du système d'information c'est très simple : gouverner c'est prévoir.
Bien cordialement,

Salut,
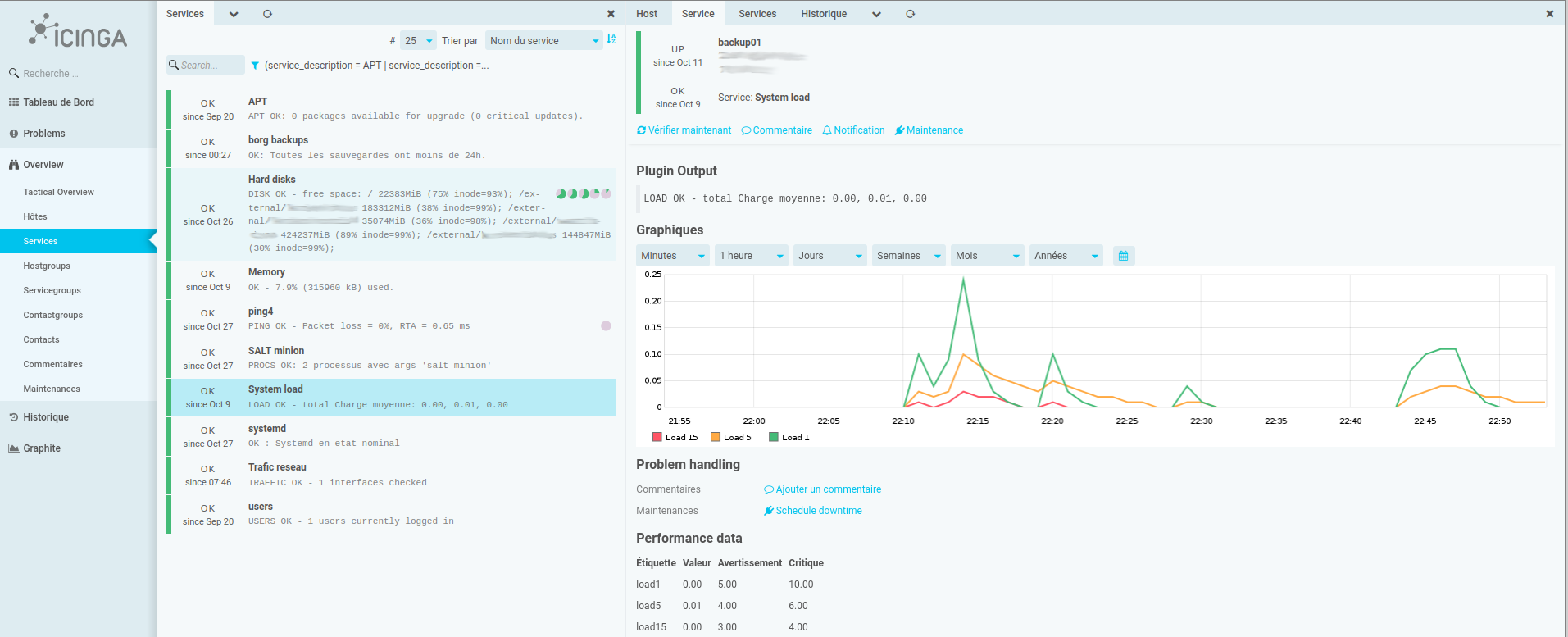
personnellement, j'utilise icinga ( https://icinga.com/ ), libre et gratuit, c'est du "nagios" amélioré en mode client/serveur (un équivalent de nagios+nrpe)
Il faut un grapheur en plus pour les graphes (j'utilise graphite : http://graphiteapp.org/ ), ça fait le job.
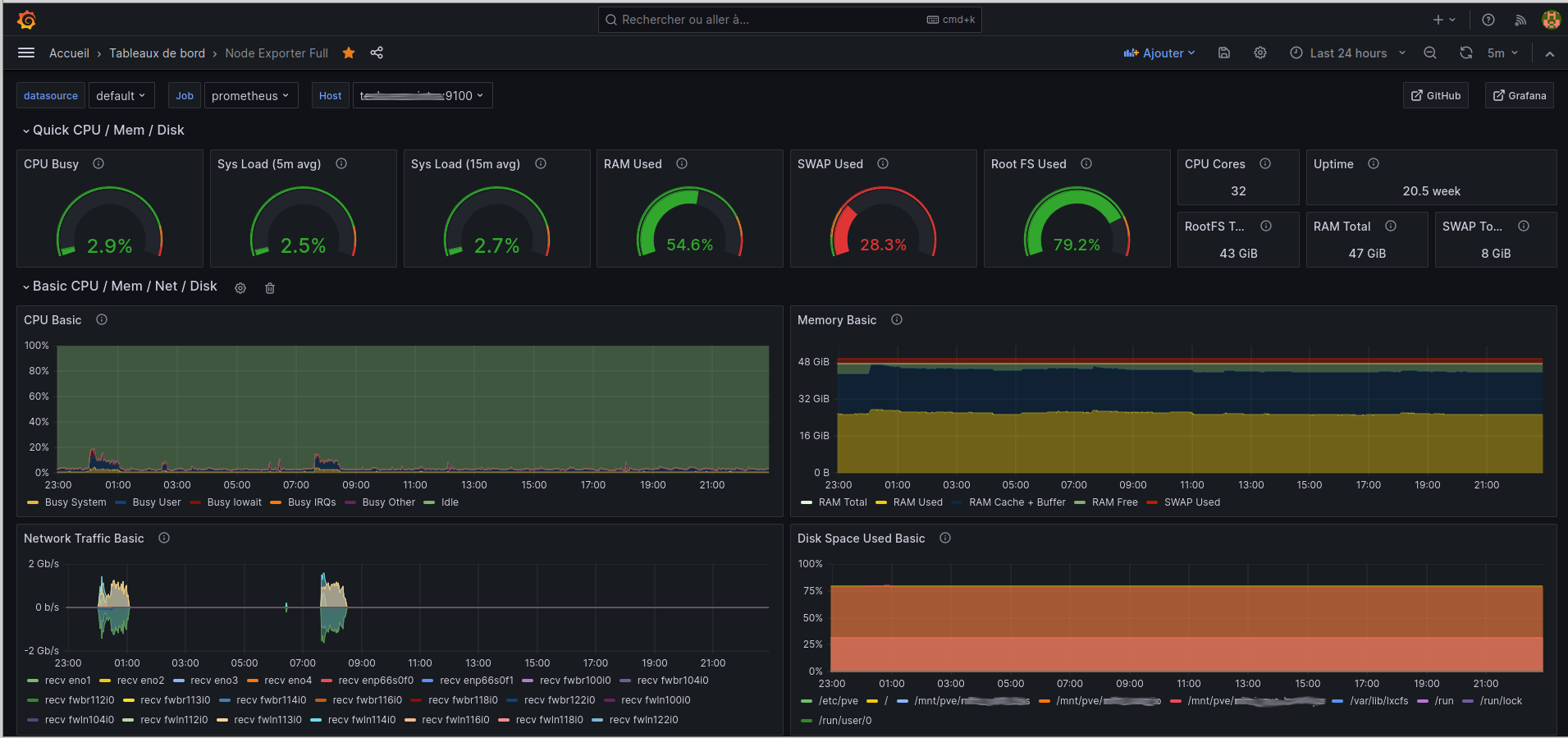
J'ai testé la combinaison prometheus+grafana et il faut dire que c'est sympa, ça "en jette" pour faire un "cockpit" de supervision :-)
Il y a un langage de requête très poussé pour définir finement les éléments supervisés, que je n'ai pas encore testé "à fond".
--
David
Le 30/10/2023 à 20:33, Jarod G. via FRsAG a écrit :
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.
Liste de diffusion du %(real_name)s http://www.frsag.org/
{kind=link}
{kind=link}

Salut,
Chez nous, même besoins et mêmes choix que tu pressens : - Observium pour capter et grapher les métriques des infras systèmes et réseaux - Grafana (et autres softs autour) pour capter les données d'état et alerter.
Plus quelques outils autour pour améliorer certaines visualisations tel que : - Smokeping pour avoir un ICMP précis et opposable à des tiers - Wanguard pour la supervision sflow du trafic de l'AS et automatiser les réponses aux attaques - Weathermap pour schématiser le réseau (module Observium, attention aux versions).
Il nous manque encore un logger performant pour centraliser les logs afin d'avoir un plan de surveillance sécurité, je sais que ça a été testé en interne mais je me souviens plus du soft.
Pour l'alerting, on a 2 méthodes : - Mails pour les trucs low et medium severity - SMS + Mail pour les trucs high ou critical severity. Pour les SMS, on a testé plein de choses (clé USB avec carte SIM, etc...) et au final, on est resté sur une bonne vielle API SMS d'OVH qu'on attaque par une connexion distincte de notre AS (4G ou freebox).
Jérémy
Le 30/10/2023 à 20:33, Jarod G. via FRsAG a écrit :
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.
Liste de diffusion du %(real_name)s http://www.frsag.org/

Aloha, Chez Neutrinet (une petite association belge) on a eu cette réflexion que nous avons documentée ici : https://wiki.neutrinet.be/fr/rapports/2021/07-04. Je pense que pour la plupart d'entre vous, on enfonce des portes ouvertes :)
Chez nous, on utilise VictoriaMetrics (https://victoriametrics.com) pour stocker les métriques au format Prometheus. Ce choix est dû que l'on voulait garder les métriques sur du temps long et pas spécialement sur du NVMe. Avec Prometheus vanilla, on avait de la corruption due à la volumétrie, la lenteur des disques et le manque de RAM.
Pour récupérer et envoyer les métriques, on passe en mode push et non pull, avec un VMAgent sur chaque machine que l'on monitore qui pousse sur le VictoriaMetrics. Ceci a comme avantage de sécuriser un endpoint et d'avoir les démons locaux aux machines qui écoute sur 127.0.xx.1. Si jamais l'endpoint de VictoriaMetrics n'est pas disponible un certain temps, les VMAgent conserve les métriques jusqu'au moment où la communication est rétablissement.
On a aussi un LibreNMS mais je ne suis pas sûr de le conserver, car les infos que l'on regarde dedans pourrait être lu dans un Grafana, même chose pour la Weathermap.
Pour les logs nous sommes en train d'expérimenter OpenObserve (https://openobserve.ai) et récemment, ils ont aussi ajouté la possibilité de récupérer des métriques au format Prometheus. L'avantage pour moi de cette solution, c'est le stockage des données sur un S3 et une alternative a la stack ELK.
Ce qui nous a pris le plus de temps, c'est la construction des tableaux de bord dans Grafana une fois que l'on sort de ceux tout fait. Pour les alertes, nous avons aussi pris du temps, mais nous nous sommes aidés de ceci : https://samber.github.io/awesome-prometheus-alerts/.
Bien à toi, Tharyrok
On 30/10/23 20:33, Jarod G. via FRsAG wrote:
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.
Liste de diffusion du %(real_name)s http://www.frsag.org/

Bonjour,
Il n'est pas *forcément* nécessaire de séparer ces deux supervisions. La plupart des outils géreront bien les deux environnements.
Par contre, j'ai une préférence à séparer supervision (aka "est-ce que mon service est rendu", notification à l'astreinte) de la métrologie (métriques, jolis graphs, aka "dans le temps, comment est-ce que ça a évolué", pas d'astreinte).
J'ai beaucoup monté des supervision à base d'Icinga2 (avec un mix d'agent icinga, de nrpe, d'icmp et de SNMP) et des métrologies avec Telegraf + victoriametrics (en remplacement d'influxdb) et grafana.
Optionnellement Icinga2 peut aussi pousser des métriques dans victoriametrics.
Le fait de séparer supervision et métrologie est d'éviter les "sondes de supervision juste pour faire des graphs, mais non ça ne sonnera pas en astreinte" qui sonneront en astreinte, et les "sondes qu'il n'est pas nécessaire de regarder" qui pollueront la vue.
J'ai aussi vu des infras avec des LibreNMS branché sur le victoriametrics pour des métriques très spécifique réseau.
Yoda-BZH
October 30, 2023 at 8:38 PM, "Jarod G. via FRsAG" frsag@frsag.org wrote:
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.
Liste de diffusion du %(real_name)s http://www.frsag.org/

Hello, De mon côté ca fait des mois que j’ai CheckMK dans mes favoris mais je ne sais pas ce que ça vaut, je n’ai pas pris le temps encore de le tester : https://checkmk.com/
La version « raw » est « free and open source ». J’aimerai l’utiliser pour remplacer un outil saas que j’utilise jusqu’ici (mais payant dont je passe le sujet).
— Kevin Labécot
Le 31 oct. 2023 à 09:14, Yoda-BZH frsag@yoda-bzh.net a écrit :
Bonjour,
Il n'est pas *forcément* nécessaire de séparer ces deux supervisions. La plupart des outils géreront bien les deux environnements.
Par contre, j'ai une préférence à séparer supervision (aka "est-ce que mon service est rendu", notification à l'astreinte) de la métrologie (métriques, jolis graphs, aka "dans le temps, comment est-ce que ça a évolué", pas d'astreinte).
J'ai beaucoup monté des supervision à base d'Icinga2 (avec un mix d'agent icinga, de nrpe, d'icmp et de SNMP) et des métrologies avec Telegraf + victoriametrics (en remplacement d'influxdb) et grafana.
Optionnellement Icinga2 peut aussi pousser des métriques dans victoriametrics.
Le fait de séparer supervision et métrologie est d'éviter les "sondes de supervision juste pour faire des graphs, mais non ça ne sonnera pas en astreinte" qui sonneront en astreinte, et les "sondes qu'il n'est pas nécessaire de regarder" qui pollueront la vue.
J'ai aussi vu des infras avec des LibreNMS branché sur le victoriametrics pour des métriques très spécifique réseau.
Yoda-BZH
October 30, 2023 at 8:38 PM, "Jarod G. via FRsAG" frsag@frsag.org wrote:
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.
Liste de diffusion du %(real_name)s http://www.frsag.org/
Liste de diffusion du %(real_name)s http://www.frsag.org/

Hello, J'avais eu l'occasion de parler de monitoring réseau à un FRnOG.
Petit contexte, une boite avec pas mal d'applicatif différent et un peu de réseau.
En gros, si on regarde ce qui se fait on a 3 type de supervision qui ce sont succèder : * Le monitoring basé sur l'alerte, c'est ce qu'on trouve dans les nagios like. Un check associé a un host qui te renvois OK ou KO, avec une touche de graphing passé au forceps * Le monitoring centré sur l'host mais basé sur les métrique : le meilleur exemple c'est zabbix, on collecte des métrique qu'on peut grapher sur un host, puis ont fait de l'alerting dessus : ** En pratique, il y a des soucis de monté a l'échelle, j'ai une boite en tête qui a taper le fond ** On peut sortir de l'host, mais c'est compliqué * le monitoring applicatif centré sur la métrique : prom like/ influxdb ** c'est de préférence l'applicatif en elle même qui remonte ses métrique ** on peut coréler nimp avec nimp (donc top) ** centré sur le graphiing, l'alerting n'est qu'une conséquence des graph
Faire le changement de paradigme est vraiment long mais totalement faisable, la plupart des softs libres ont des exporter prometheus, et fournir au dev un framwork pour exporter de la métrique métier ça facilite la vie de ouf sur l'astreinte.
En 2023 sur une nouvelle infra, il faut clairement partir sur ce paradigme. Néanmoins un point important, si il faut faire de la rétention de métrique sur une longue durée prometheus n'est pas adapté ça et je suggére de regarder du coté de victoriametric ou de thanos.io ou de mimir (soutenue par grafana).
A noté aussi que même pour le réseau il existe des exporteur pour parser du SNMP, et pour le ping il y a le blackbox exporter. Alexis
Le mar. 31 oct. 2023 à 09:21, Kevin Labécot kevin@labecot.fr a écrit :
Hello, De mon côté ca fait des mois que j’ai CheckMK dans mes favoris mais je ne sais pas ce que ça vaut, je n’ai pas pris le temps encore de le tester : https://checkmk.com/
La version « raw » est « free and open source ». J’aimerai l’utiliser pour remplacer un outil saas que j’utilise jusqu’ici (mais payant dont je passe le sujet).
— Kevin Labécot
Le 31 oct. 2023 à 09:14, Yoda-BZH frsag@yoda-bzh.net a écrit :
Bonjour,
Il n'est pas *forcément* nécessaire de séparer ces deux supervisions. La plupart des outils géreront bien les deux environnements.
Par contre, j'ai une préférence à séparer supervision (aka "est-ce que mon service est rendu", notification à l'astreinte) de la métrologie (métriques, jolis graphs, aka "dans le temps, comment est-ce que ça a évolué", pas d'astreinte).
J'ai beaucoup monté des supervision à base d'Icinga2 (avec un mix d'agent icinga, de nrpe, d'icmp et de SNMP) et des métrologies avec Telegraf + victoriametrics (en remplacement d'influxdb) et grafana.
Optionnellement Icinga2 peut aussi pousser des métriques dans victoriametrics.
Le fait de séparer supervision et métrologie est d'éviter les "sondes de supervision juste pour faire des graphs, mais non ça ne sonnera pas en astreinte" qui sonneront en astreinte, et les "sondes qu'il n'est pas nécessaire de regarder" qui pollueront la vue.
J'ai aussi vu des infras avec des LibreNMS branché sur le victoriametrics pour des métriques très spécifique réseau.
Yoda-BZH
October 30, 2023 at 8:38 PM, "Jarod G. via FRsAG" frsag@frsag.org wrote:
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.
Liste de diffusion du %(real_name)s http://www.frsag.org/
Liste de diffusion du %(real_name)s http://www.frsag.org/
Liste de diffusion du %(real_name)s http://www.frsag.org/

Je rejoins tout ce qui a été dit. La paradigme est d'utiliser de la métrologie (donc basé sur la métrique en pull ou push). Le standard de facto de nos jours est Prometheus (ou Opentelemetry). Je conseille vivement sur des nouvelles installations de ne pas se prendre la tête et de partir directement sur du VictoriaMetrics (qui est très efficace).
Meme pour le réseau il y en effet des exporteurs snmp, et pour la partie flow on peut bricoler rapidement un exporteur aussi (j'avais fait le mien à l’époque à base de pmacct, kafka, python).
Un point toutefois bien mis en avant dans la littérature google (https://sre.google/sre-book/monitoring-distributed-systems/) le white-box et monitoring passif ne suffit pas.
A mon sens il faut toujours garder du monitoring actif black-box externe quand c'est possible.
Cdt,
-- Raphael Mazelier
On 31/10/2023 10:40, Alexis Lameire wrote:
Hello, J'avais eu l'occasion de parler de monitoring réseau à un FRnOG.
Petit contexte, une boite avec pas mal d'applicatif différent et un peu de réseau.
En gros, si on regarde ce qui se fait on a 3 type de supervision qui ce sont succèder :
- Le monitoring basé sur l'alerte, c'est ce qu'on trouve dans les nagios like. Un check associé a un host qui te renvois OK ou KO, avec une touche de graphing passé au forceps
- Le monitoring centré sur l'host mais basé sur les métrique : le meilleur exemple c'est zabbix, on collecte des métrique qu'on peut grapher sur un host, puis ont fait de l'alerting dessus :
** En pratique, il y a des soucis de monté a l'échelle, j'ai une boite en tête qui a taper le fond ** On peut sortir de l'host, mais c'est compliqué
- le monitoring applicatif centré sur la métrique : prom like/ influxdb
** c'est de préférence l'applicatif en elle même qui remonte ses métrique ** on peut coréler nimp avec nimp (donc top) ** centré sur le graphiing, l'alerting n'est qu'une conséquence des graph
Faire le changement de paradigme est vraiment long mais totalement faisable, la plupart des softs libres ont des exporter prometheus, et fournir au dev un framwork pour exporter de la métrique métier ça facilite la vie de ouf sur l'astreinte.
En 2023 sur une nouvelle infra, il faut clairement partir sur ce paradigme. Néanmoins un point important, si il faut faire de la rétention de métrique sur une longue durée prometheus n'est pas adapté ça et je suggére de regarder du coté de victoriametric ou de thanos.io ou de mimir (soutenue par grafana).
A noté aussi que même pour le réseau il existe des exporteur pour parser du SNMP, et pour le ping il y a le blackbox exporter. Alexis
Le mar. 31 oct. 2023 à 09:21, Kevin Labécot kevin@labecot.fr a écrit :
Hello, De mon côté ca fait des mois que j’ai CheckMK dans mes favoris mais je ne sais pas ce que ça vaut, je n’ai pas pris le temps encore de le tester : https://checkmk.com/
La version « raw » est « free and open source ». J’aimerai l’utiliser pour remplacer un outil saas que j’utilise jusqu’ici (mais payant dont je passe le sujet).
— Kevin Labécot
Le 31 oct. 2023 à 09:14, Yoda-BZH frsag@yoda-bzh.net a écrit :
Bonjour,
Il n'est pas *forcément* nécessaire de séparer ces deux supervisions. La plupart des outils géreront bien les deux environnements.
Par contre, j'ai une préférence à séparer supervision (aka "est-ce que mon service est rendu", notification à l'astreinte) de la métrologie (métriques, jolis graphs, aka "dans le temps, comment est-ce que ça a évolué", pas d'astreinte).
J'ai beaucoup monté des supervision à base d'Icinga2 (avec un mix d'agent icinga, de nrpe, d'icmp et de SNMP) et des métrologies avec Telegraf + victoriametrics (en remplacement d'influxdb) et grafana.
Optionnellement Icinga2 peut aussi pousser des métriques dans victoriametrics.
Le fait de séparer supervision et métrologie est d'éviter les "sondes de supervision juste pour faire des graphs, mais non ça ne sonnera pas en astreinte" qui sonneront en astreinte, et les "sondes qu'il n'est pas nécessaire de regarder" qui pollueront la vue.
J'ai aussi vu des infras avec des LibreNMS branché sur le victoriametrics pour des métriques très spécifique réseau.
Yoda-BZH
October 30, 2023 at 8:38 PM, "Jarod G. via FRsAG" frsag@frsag.org wrote:
Holà la liste,
on est en train de réfléchir à la question des supervisions pour une petite infra qui peut être amenée à évoluer.
Je dit "des" car on remarque vite que un outil tout en un qui fait tout correctement, bah ça existe tout simplement pas.
On réfléchissait à monter donc au moins deux sups.
Une sup "infra" qui fait uniquement du SNMP/ICMP pour tout ce qui est réseau/serveurs/vm et une sup "applicative" qui elle va gérer le reste (état nginx, systemd, etc...).
Du coup on est en recherche d'idées, sur la partie "infra" on est plutôt familier avec Observium et LibreNMS même si on est pas fermé à autre chose. Quand à la partie "applicative" c'est un peu le flou (mix grafana+influx ?), surtout sur la partie alertes.
Avez vous des retex sur des solutions que vous utilisez déjà ? (ou des noms de solutions "entendues" mais jamais testées)
Notre seule et unique contrainte dans les solutions est que ça a besoin d'être gratuit (bonus si c'est libre).
Jarod G.
Liste de diffusion du %(real_name)s http://www.frsag.org/
Liste de diffusion du %(real_name)s http://www.frsag.org/
Liste de diffusion du %(real_name)s http://www.frsag.org/
-
 Alexis Lameire
Alexis Lameire -
 David
David -
 Jarod G.
Jarod G. -
 Jeremy
Jeremy -
 Kevin Labécot
Kevin Labécot -
 Maxime DERCHE
Maxime DERCHE -
 Raphael Mazelier
Raphael Mazelier -
 Tharyrok
Tharyrok -
 Yoda-BZH
Yoda-BZH